

软件包@ckeditor/ckeditor5-engine是迄今为止最大的内置框架。本指南仅介绍其主要的架构层和概念,更详细的指南会在之后陆续推出。
建议使用官方的 CKEditor 5 Inspector 进行开发和调试。它会提供大量有关编辑器状态的有用信息,如内部数据结构、选区和指令等。
概览
编辑引擎采用模型-视图-控制器(MVC)架构。引擎本身并不强制要求其符合某具体的形态,但在大多数实现中,其都可以用下面的图表来描述:
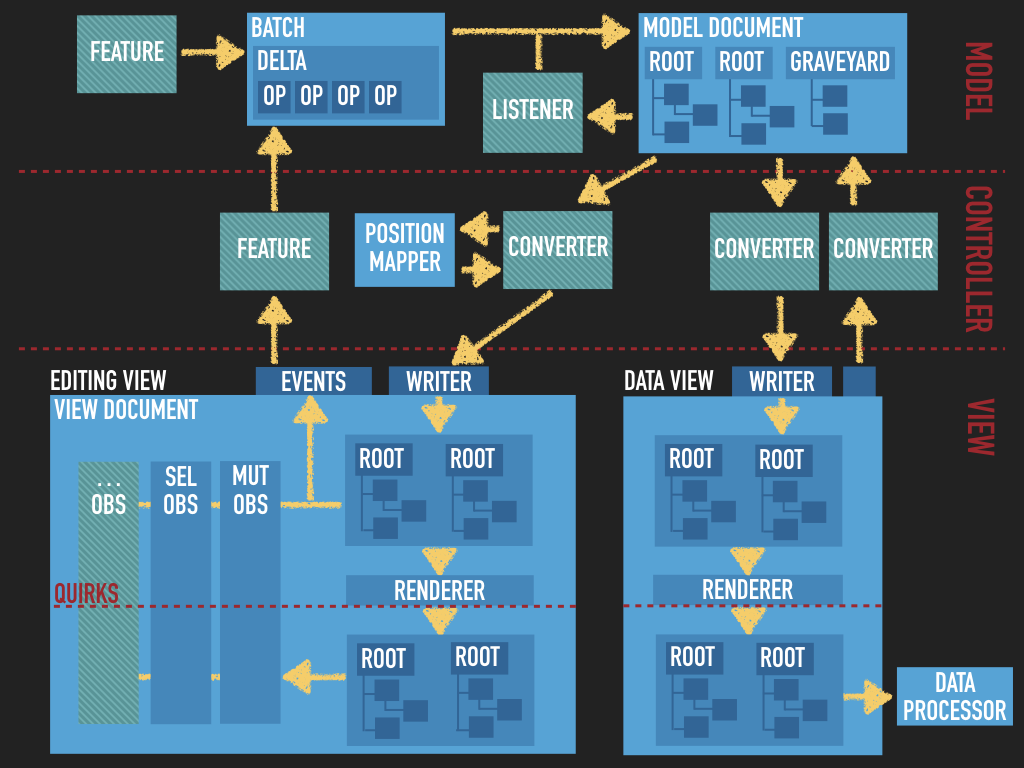
上图有三个层次:模型 Model、控制器 Controller 和视图 View。其中一个模型文档 Model Document 被转换成不同的视图——编辑视图 Editing View 和数据视图 Data View。这两个视图分别代表用户正在编辑的内容(在浏览器中可观察到的 DOM 结构)和编辑器的输入输出数据(插件数据处理器能理解的格式)。这两个视图都具有虚拟 DOM 结构,转换器和功能基于此虚拟 DOM 工作,然后再渲染到 DOM 中。
所有绿色的区块都是编辑器功能(插件)能够引入的代码。这些功能可以控制对模型做出哪些更改,如何将更改转换到视图,以及如何根据触发的事件(视图事件和模型事件)更改模型。现在让我们分别谈谈每一层。
模型层
模型由类似 DOM 的元素和文本节点树结构实现。与实际 DOM 不同,在模型中,元素和文本节点都可以有属性。
与 DOM 一样,模型结构包含在一个文档中,该文档包含根元素(模型和视图可能有多个根元素)。文档还包含其选区和更改历史。文档、其模式和文档标签都是模型的属性。在editor.model属性中可以找到模型类的实例。除了持有上述属性外,模型还提供了修改文档及其标签的 API。
editor.model; // -> 数据模型
editor.model.document; // -> 文档
editor.model.document.getRoot(); // -> 文档的根元素
editor.model.document.selection; // -> 文档当前的选区
editor.model.schema; // -> 文档的模式修改模型
文档结构、文档选区甚至元素创建的所有更改都只能通过使用 Model Writer 来完成。其实例可在change()和enqueueChange()块中使用。
// 在当前选区的位置插入文本 “foo”
editor.model.change( writer => {
writer.insertText( 'foo', editor.model.document.selection.getFirstPosition() );
} );
// 为整个选区应用加粗
editor.model.change( writer => {
for ( const range of editor.model.document.selection.getRanges() ) {
writer.setAttribute( 'bold', true, range );
}
} );单个change()块中的所有更改都会合并到一个撤销步骤中(它们会被添加到一个批处理中)。嵌套change()块时,所有更改都会添加到最外层change()块的批次。
下面的代码能够创建一个撤销步骤:
editor.model.change( writer => {
writer.insertText( 'foo', paragraph, 'end' ); // foo
editor.model.change( writer => {
writer.insertText( 'bar', paragraph, 'end' ); // foobar
} );
writer.insertText( 'bom', paragraph, 'end' ); // foobarbom
} );对文档结构的所有更改都是通过应用操作完成的。操作的概念来自于“操作转换”,简称 OT。这是一种支持协作功能的技术。由于 OT 要求系统能够通过每一个其它操作对每一个操作进行转换(以找出同时应用操作的结果),因此操作集必须很小。CKEditor 5 采用的是非线性模型(通常 OT 实现使用的是平面、数组式模型,而 CKEditor 5 使用的是树形结构),因此潜在的语义变化集更为复杂。操作按批次分组。一个批次可以理解为一个撤消步骤。
文本属性
文本样式如 “粗体 ”和 “斜体”,不是作为元素——而是作为文本属性(就像元素属性一样)保存在模型中。下面是 DOM 结构:
<p> "Foo " <strong> "bar" </strong> </p>其将转化为如下模型结构:
<paragraph>
"Foo " // 文本节点
"bar" // 文本节点,其 bold 属性为 true
</paragraph>这种内联文本样式的表示方法可以大大降低在模型上运行算法的复杂性。例如如果对于上面的 DOM 结构:
<p> "Foo " <strong> "bar" </strong> </p>现在我们的选区位于字母 b 前方,即Foo ^bar,那么这个位置究竟是在<strong>内部还是外部?如果使用原生 DOM 逻辑,那么会同时得到两个位置:一个锚定在标签<p>内部,另一个锚定在标签<strong>内部。但在 CKEditor 5 中,这个位置将会被精确地翻译成Foo ^bar。
选区属性
在上述情况下,如何让 CKEditor 5 知道我们希望选区“加粗 ”呢?这个问题非常关键,因为它会影响在这之后键入的文本是否也是粗体。
为了处理这个问题,选区也有属性。如果将选区置于Foo ^bar中,且其属性为bold=true,那么用户输入的文本将是粗体。
索引和偏移
刚才已经说过,在<paragraph>中有两个文本节点:Foo和bar。如果我们知道原生 DOM 选区范围是如何工作的,则可能会发问:“如果选区位于两个文本节点的边界,那么它是锚定在左边的节点、右边的节点,还是只视为锚定在上层元素中?”事实上这是 DOM API 的另一个问题。某些元素外部和内部的位置不仅在视觉上可能完全相同,而且还可能(若其位于文本节点边界)锚定在文本节点内部或外部。这一切都给编辑算法的实施带来了极大的麻烦。为了避免这些麻烦,并使协同编辑真正成为可能,CKEditor 5 使用了索引和偏移的概念。索引与节点(元素和文本节点)有关,而偏移则与位置有关。例如,在以下结构中:
<paragraph>
"Foo "
<imageInline></imageInline>
"bar"
</paragraph>文本节点Foo在其父节点中位于索引0,<imageInline></imageInline>位于索引1,而bar位于索引2。
另一方面,<paragraph>中的偏移量x可转换为:
| 偏移量 | 位置 | 节点 |
|---|---|---|
0 | <paragraph>^Foo <imageInline></imageInline>bar</paragraph> | "Foo " |
1 | <paragraph>F^oo <imageInline></imageInline>bar</paragraph> | "Foo " |
4 | <paragraph>Foo ^<imageInline></imageInline>bar</paragraph> | <imageInline> |
6 | <paragraph>Foo <imageInline></imageInline>b^ar</paragraph> | "bar" |
位置、范围和选区
引擎还定义了三层对偏移量进行操作的类:
- 实例 Position 包含一个偏移数组,一般称其为路径(Path);
- 实例 Range 包含两个位置:起始位置和终止位置;
- 实例 Selection 包含一个或多个范围(Range)、属性(Attributes)和一个方向(Direction)(从左到右还是从右到左)。
DocumentSelection。它代表整个文档的选区,只能通过 Model Writer 进行更改。当文档结构发生变化时,它会自动更新。标签
标签是范围的一种特殊类型。
- 它们由 MarkerCollection 管理,且只能通过 Model Writer 创建和更改;
- 标签可以通过网络与其它协作客户端同步;
- 当文档结构发生变化时,它们会自动更新;
- 可以将它们转换为编辑视图,以便在编辑器中(突出)显示它们;
- 它们可以转换为数据视图,与文档数据一起存储;
- 它们可以与文档数据一起加载。
模式
模型的模式定义了模型的几个表征方面:
- 允许或不允许节点的位置。例如,允许在
$root中使用paragraph,但不允许在heading1中使用; - 某个节点允许使用哪些属性。例如,图片可以有
src和alt属性; - 模型节点的其它语义。例如,图片属于“对象 ”类型,段落属于“块 ”类型。
- 节点可以在某些位置被禁用。例如自定义元素
specialParagraph继承了paragraph的所有属性,但需要禁止imageInline; - 可以禁止在特定节点上使用属性。例如自定义元素
specialPurposeHeading继承了heading2的属性,但不允许使用对齐属性。
- 粘贴的内容会发生什么,哪些会被过滤掉。注意:在粘贴的情况下,另一个重要机制是转换(Convert)。所加载的 HTML 元素和属性,若其未被任何转换器注册,则在成为模型节点之前就会被过滤掉,因此模式不会作用于它们。本指南稍后将介绍转换;
- 哪些元素可以使用标题功能(哪些块可以转为标题,哪些元素首先是块);
- 哪些元素可以使用引用型区块(Block Quote)封装;
- 当选区位于标题中时,是否启用加粗按钮(以及该标题中的文本是否可以加粗);
- 选区可以放置在什么位置(只能放在文本节点和对象元素中);
- 等等。
editor.model.schema,不过需要重构编辑器。视图
再来看下之前的架构图:
模型层的作用是对数据进行抽象,其格式的设计是为了以最方便的方式存储和修改数据,同时实现复杂的功能。大多数功能都是对模型进行操作(读取和修改)。
另一方面,视图是 DOM 结构的抽象表示,它应该呈现给用户以用于编辑,并且在大多数情况下代表编辑器的输入和输出,即editor.getData()返回的数据、editor.setData()设置的数据、粘贴的内容等。这意味着:
- 视图是另一种自定义结构;
- 视图类似于 DOM。模型的树形结构只是与 DOM 略微相似,而视图则更接近 DOM。换句话说,它是一个虚拟 DOM;
- 视图拥有两个管道(Pipeline):编辑管道(Editing Pipeline),也称为编辑视图(Editing View),和数据管道(Data Pipeline),也成为数据视图(Data View)。应将它们视为一个模型的两个独立视图。编辑管道渲染并处理用户看到并可以编辑的 DOM。数据管道用于调用
editor.getData()、editor.setData()或将内容粘贴到编辑器中。 - 视图由渲染器(Renderer)渲染至 DOM,渲染器会处理编辑管道中所使用的
contentEditable所需的所有对象。
editor.editing; // 编辑管道——EditingController
editor.editing.view; // 编辑视图的控制器
editor.editing.view.document; // 编辑视图的文档
editor.data; // 数据管道——DataController从技术上来讲,数据管道没有文档和视图控制器,它是在为处理数据而创建的独立视图结构上运行的,它比编辑管道简单得多。
元素类型和自定义数据
视图的结构与 DOM 的结构非常相似。HTML 的语义已在其规范中定义。视图结构是“无 DTD ”的,因此为了提供更多信息、更好地表达内容的语义,视图结构实现了六种元素类型(ContainerElement、AttributeElement、EmptyElement、RawElement、UIElement和EditableElement)和所谓的“自定义属性”,即不渲染的自定义元素属性)。渲染器和转换器将使用编辑器功能提供的这些附加信息。元素类型定义如下:
| 类型 | 机读名称 | 描述 |
|---|---|---|
| 容器元素 | Container Element | 用于构建内容结构的元素,常为块级元素,如<p>、<h1>、<blockQuote>、<li>等 |
| 属性元素 | Attribute Element | 不能在其中包含容器元素的元素。大多数模型文本属性都会转换为属性元素。 其主要用于内联样式元素,如 |
| 空元素 | Empty Element | 必定不包含任何子节点的元素,如<img> |
| 用户界面元素 | UI Element | 不是数据的一部分,但需要在内容中内联的元素。选区和一般的 View Writer 会忽略它们。 这些元素的内容和来自它们的事件也会被过滤掉。 |
| 原始元素 | Raw Element | 作为数据容器工作的元素,但其子元素对编辑器是透明的。当必须呈现非标准数据,但编辑器不应关心它是什么以及如何工作时会用到。用户不能将选区放入原始元素中,也不能将其进一步分割,或直接修改其内容。 |
| 可编辑元素 | Editable Element | 作为不可编辑内容片段的“嵌套可编辑元素 ”使用的元素。如图片小部件中的标题,其中包裹图片的<figure>是不可编辑的,因其是一个小部件。而其内部的<figcaption>则是一个可编辑元素。 |
此外还可以定义自定义属性,用于存储以下信息:
- 元素是否是小部件(Widget)。通过
toWidget()添加; - 当一个 Marker 高亮元素时,应如何标记该元素;
- 元素是否属于某个功能——如链接、进度条和标题等。
非语义视图
并非所有视图树都需要使用语义元素类型来构建。直接从输入数据(例如从剪贴板获取的 HTML 或使用editor.setData())生成的视图结构只包含基本元素实例。这些视图结构通常会转换为模型结构,然后再转换回视图结构,以便进行编辑或数据检索,这时它们又会变成语义视图。
语义视图中传达的额外信息,以及开发人员希望在这些树上执行的特殊类型操作,意味着这两种结构都需要由不同的工具来修改。
修改视图
除非你真的知道自己在做什么,否则不要手动修改视图。如果需要更改视图,在大多数情况下,应首先更改其模型,然后通过特定的转换器(Converter)将应用于模型的更改转换到视图中。如果修改的原因在模型中没有体现,则可能需要手动修改视图。例如:模型中没有存储有关焦点的信息,而焦点是视图的一个属性。当焦点发生变化时,如果想在某个元素的类中表示出来,就需要手动更改该类。
为此,就像在模型中一样,应该使用(视图的)change()块,在该块中可以访问视图下播写入器(View Downcast Writer)。
editor.editing.view.change( writer => {
writer.insert( position, writer.createText( 'foo' ) );
} );有两种视图写入器:
下播写入器(Downcast Writer):可在change()块中使用,用于将模型下播到视图。它基于语义视图运行,因此视图结构可以区分不同类型的元素;
上播写入器(UpcastWriter):用于预处理输入数据(如粘贴的内容),通常发生在转换上播到模型之前。它对非语义视图进行操作。
位置
就像在模型中一样,视图中有三个级别的类来描述视图结构中的点:位置(Position)、范围(Range)和选区(Selection)。位置是文档中的一个点,范围由两个位置:起点和终点组成。一个选区由一个或多个范围组成,且携带一个方向:是从左到右还是从右到左。
视图范围与 DOM 中的视图范围类似,视图位置由父节点和父节点中的偏移量表示。这意味着视图偏移量与模型偏移量不同。其描述的是:
- 对于位置的父节点,若其有子节点,则描述子节点之间的缝隙;
- 对于位置的父节点,若其为文本节点,则描述文本节点字符之间的缝隙。
| 父对象 | 偏移量 | 位置 |
|---|---|---|
<p> | 0 | <p>^Foo<img></img>bar</p> |
<p> | 1 | <p>Foo^<img></img>bar</p> |
<p> | 2 | <p>Foo<img></img>^bar</p> |
<img> | 0 | <p>Foo<img>^</img>bar</p> |
Foo | 1 | <p>F^oo<img></img>bar</p> |
Foo | 3 | <p>Foo^<img></img>bar</p> |
正如所看到的,其中两个位置代表了文档中的同一个缝隙:
{ parent: paragraphElement, offset: 1 }{ parent: fooTextNode, offset: 3 }
DOM 位置的表示远非那么方便,这也是我们思考和使用模型位置的另一个原因。
观察器
为了给本地 DOM 事件创建一个更安全、更有用的抽象,视图实现了观察器(Observer)的概念。它通过将本地事件转换为更有用的形式,提高了编辑器的可测试性,并简化了编辑器功能添加的监听器。观察器监听一个或多个 DOM 事件,对事件进行初步处理,然后在视图文档上触发自定义事件。观察器不仅会对事件本身进行抽象,还会对其数据进行抽象。理想情况下,事件的消费者不应访问本地 DOM。
默认情况下,视图会添加以下观察器:
- MutationObserver
- SelectionObserver
- FocusObserver
- KeyObserver
- FakeSelectionObserver
- CompositionObserver
- ArrowKeysObserver
ClipboardObserver。可以使用view.addObserver()方法添加自己的观察器(应为Observer的子类)。要了解如何编写观察器,可以查看现有观察器的代码。此外鉴于所有事件默认都是在 Document 上触发,因此建议第三方软件包在事件前加上项目的标识符,以避免名称冲突。例如MyApp应触发myApp:keydown而不是keydown。
转换
模型和视图被视为两个完全独立的子系统,但它们可以被连接起来。这两层系统相遇的三种主要情况是:
| 转换机制名称 | 英文名称 | 描述 |
|---|---|---|
| 数据上播 | Data upcasting | 向编辑器加载数据。 首先,数据(如 HTML 字符串)由 |
| 数据下播 | Data downcasting | 从编辑器中读取数据。 首先将模型根的内容转换为视图文档碎片。然后数据处理器将视图文档碎片处理为目标数据格式。 |
| 编辑下播 | Editing downcasting | 将编辑器内容渲染给用户编辑区。 这个过程在编辑器初始化的整个过程中都会发生。首先,数据上播完成后,模型根会转换为视图根。然后视图根会在编辑器的 |
再来看看引擎的 MVC 架构图,观察其中每个转换流程的位置:
数据管道
数据上播是从图片的右下角(视图层)开始,通过控制器层中的转换器(绿框)从数据视图传递到右上角的模型文档的过程。正如所见,其自底向上传递,因此称为上播。此外,其由数据管道(图中右侧分支)处理,因此称为数据上播。注:数据上播也用于处理粘贴的内容(类似于加载数据)。
数据下播是与数据上播相反的流程。它从右上角开始,一直到右下角。同样,转换过程的名称与方向和管道相匹配。
编辑管道
编辑下播与其它两个过程有些不同。
- 它发生在编辑流水线,即图中的左侧分支中;
- 它没有对应的流程;
- 没有编辑上播,因为所有用户操作都是由编辑器功能通过监听视图事件、分析发生的情况并对模型进行必要更改来处理的。因此这一过程不涉及转换。